调试 HTML
编写 HTML 没问题,但是如果出了问题,并且你无法找出代码中的错误位置怎么办?本文将向你介绍一些可以帮助你查找和修复 HTML 中的错误的工具。
¥Writing HTML is fine, but what if something goes wrong, and you can't work out where the error in the code is? This article will introduce you to some tools that can help you find and fix errors in HTML.
| 先决条件: | 熟悉 HTML,例如 HTML 入门、 HTML 文本基础知识 和 创建超链接 中介绍的内容。 |
|---|---|
| 目标: | 了解使用调试工具查找 HTML 中问题的基础知识。 |
调试并不可怕
¥Debugging isn't scary
当编写某种代码时,一切通常都很好,直到发生错误的可怕时刻 - 你做错了什么,所以你的代码无法工作 - 要么根本不工作,要么不完全按照你想要的方式工作。例如,下面显示了尝试 compile 一个用 Rust 语言编写的简单程序时报告的错误。
¥When writing code of some kind, everything is usually fine, until that dreaded moment when an error occurs — you've done something wrong, so your code doesn't work — either not at all, or not quite how you wanted it to. For example, the following shows an error reported when trying to compile a simple program written in the Rust language.

这里,错误信息比较容易理解 - "未终止的双引号字符串"。如果你查看清单,你可能会发现 println!(Hello, world!"); 在逻辑上可能缺少双引号。然而,随着程序变得越来越大,错误消息很快就会变得更加复杂并且更难以解释,甚至对于那些对 Rust 一无所知的人来说,即使是简单的情况也会显得有点令人生畏。
¥Here, the error message is relatively easy to understand — "unterminated double quote string". If you look at the listing, you can probably see how println!(Hello, world!"); might logically be missing a double quote. However, error messages can quickly get more complicated and less easy to interpret as programs get bigger, and even simple cases can look a little intimidating to someone who doesn't know anything about Rust.
不过,调试并不一定很可怕 - 熟悉编写和调试任何编程语言或代码的关键是熟悉该语言和工具。
¥Debugging doesn't have to be scary though — the key to being comfortable with writing and debugging any programming language or code is familiarity with both the language and the tools.
HTML 和调试
¥HTML and debugging
HTML 并不像 Rust 那样难以理解。在浏览器解析 HTML 并显示结果之前,HTML 不会被编译成不同的形式(它是被解释的,而不是被编译的)。HTML 的 element 语法可以说比 Rust、JavaScript 或 Python 等 "真正的编程语言" 语法更容易理解。浏览器解析 HTML 的方式比编程语言的运行方式要宽松得多,这既是好事也是坏事。
¥HTML is not as complicated to understand as Rust. HTML is not compiled into a different form before the browser parses it and shows the result (it is interpreted, not compiled). And HTML's element syntax is arguably a lot easier to understand than a "real programming language" like Rust, JavaScript, or Python. The way that browsers parse HTML is a lot more permissive than how programming languages are run, which is both a good and a bad thing.
许可代码
¥Permissive code
那么我们所说的宽容是什么意思?嗯,通常,当你在代码中犯错时,你会遇到两种主要类型的错误:
¥So what do we mean by permissive? Well, generally when you do something wrong in code, there are two main types of error that you'll come across:
- 语法错误:这些是代码中的拼写或标点错误,实际上会导致程序无法运行,如上面显示的 Rust 错误。只要你熟悉该语言的语法并知道错误消息的含义,这些问题通常很容易修复。
- 逻辑错误:这些错误的语法实际上是正确的,但代码不是你想要的,这意味着程序运行不正确。这些错误通常比语法错误更难修复,因为没有错误消息可以指导你找到错误的根源。
HTML 本身不会出现语法错误,因为浏览器会宽容地解析它,这意味着即使存在语法错误,页面仍然会显示。浏览器有内置规则来说明如何解释错误编写的标记,因此即使它不是你所期望的,你也会运行一些东西。当然,这仍然是一个问题!
¥HTML itself doesn't suffer from syntax errors because browsers parse it permissively, meaning that the page still displays even if there are syntax errors. Browsers have built-in rules to state how to interpret incorrectly written markup, so you'll get something running, even if it is not what you expected. This, of course, can still be a problem!
注意:HTML 是被允许解析的,因为当网络第一次创建时,人们决定允许人们发布他们的内容比确保语法绝对正确更重要。如果从一开始就更加严格的话,网络可能不会像今天这样受欢迎。
¥Note: HTML is parsed permissively because when the web was first created, it was decided that allowing people to get their content published was more important than making sure the syntax was absolutely correct. The web would probably not be as popular as it is today, if it had been more strict from the very beginning.
主动学习:研究许可代码
¥Active learning: Studying permissive code
是时候研究 HTML 代码的宽容性质了。
¥It's time to study the permissive nature of HTML code.
- 首先,下载我们的 调试示例演示 并保存在本地。这个演示是故意编写的,带有一些内置错误供我们探索(据说 HTML 标记格式错误,而不是格式良好)。
- 接下来,在浏览器中打开它。你会看到类似这样的内容:
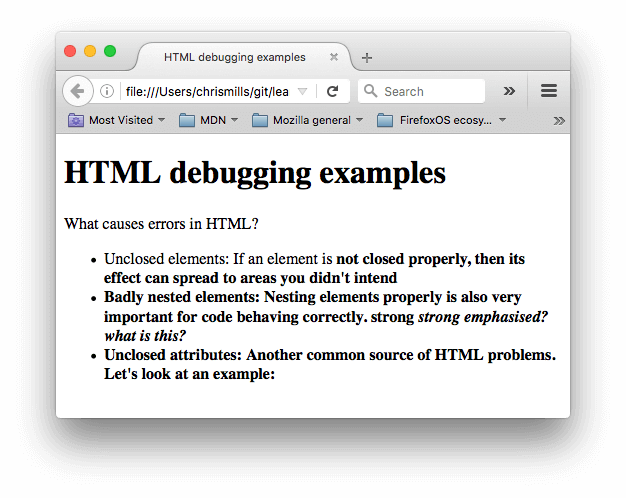
- 这看起来不太好;让我们看一下源代码,看看是否可以找出原因(仅显示正文内容):
html
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasized?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> - 我们来回顾一下存在的问题:
- 现在让我们看看浏览器呈现的标记,而不是源代码中的标记。为此,我们可以使用浏览器开发者工具。如果你不熟悉如何使用浏览器的开发者工具,请花几分钟时间查看 探索浏览器开发者工具。
- 在 DOM 检查器中,你可以看到渲染的标记是什么样子的:

- 使用 DOM 检查器,让我们详细探索我们的代码,看看浏览器如何尝试修复 HTML 错误(我们在 Firefox 中进行了审查;其他现代浏览器应该给出相同的结果):
- 段落和列表项已被赋予结束标签。
- 目前尚不清楚第一个
<strong>元素应该在哪里关闭,因此浏览器用自己的强标签封装了每个单独的文本块,一直到文档的底部! - 浏览器已修复不正确的嵌套,如下所示:
html
<strong> strong <em>strong emphasized?</em> </strong> <em> what is this?</em> - 缺少双引号的链接已被完全删除。最后一个列表项如下所示:
html
<li> <strong> Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
HTML 验证
¥HTML validation
因此,从上面的示例中你可以看出,你确实希望确保 HTML 格式良好!但如何呢?在像上面这样的小例子中,很容易通过行搜索并找到错误,但是对于一个巨大的、复杂的 HTML 文档呢?
¥So you can see from the above example that you really want to make sure your HTML is well-formed! But how? In a small example like the one seen above, it is easy to search through the lines and find the errors, but what about a huge, complex HTML document?
最好的策略是首先通过 标记验证服务 运行 HTML 页面 - 由 W3C 创建和维护,该组织负责定义 HTML、CSS 和其他 Web 技术的规范。该网页将 HTML 文档作为输入,对其进行检查,并提供一份报告来告诉你 HTML 存在什么问题。
¥The best strategy is to start by running your HTML page through the Markup Validation Service — created and maintained by the W3C, the organization that looks after the specifications that define HTML, CSS, and other web technologies. This webpage takes an HTML document as an input, goes through it, and gives you a report to tell you what is wrong with your HTML.

要指定要验证的 HTML,你可以提供网址、上传 HTML 文件或直接输入一些 HTML 代码。
¥To specify the HTML to validate, you can provide a web address, upload an HTML file, or directly input some HTML code.
主动学习:验证 HTML 文档
¥Active learning: Validating an HTML document
让我们用 样本文件 试试这个。
¥Let's try this with our sample document.
这应该会为你提供错误列表和其他信息。
¥This should give you a list of errors and other information.
解释错误消息
¥Interpreting the error messages
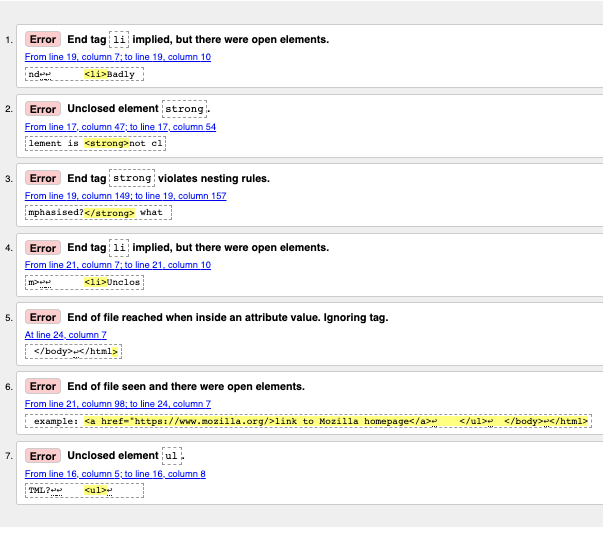
错误消息通常很有帮助,但有时却没有那么有用;通过一些练习,你可以弄清楚如何解释这些内容来修复你的代码。让我们浏览一下错误消息并了解它们的含义。你将看到每条消息都带有行号和列号,以帮助你轻松找到错误。
¥The error messages are usually helpful, but sometimes they are not so helpful; with a bit of practice you can work out how to interpret these to fix your code. Let's go through the error messages and see what they mean. You'll see that each message comes with a line and column number to help you to locate the error easily.
- “隐含结束标记
li,但存在开放元素”(2 个实例):这些消息表明某个元素已打开,应关闭。结束标签是隐含的,但实际上并不存在。行/列信息指向结束标记真正所在的行之后的第一行,但这是一个足够好的线索来查看问题所在。 - “未封闭元素
strong”:这真的很容易理解 -<strong>元素是未封闭的,行/列信息直接指向它所在的位置。 - “结束标记
strong违反了嵌套规则”:这指出了错误嵌套的元素,并且行/列信息指出了它们的位置。 - “在属性值内时到达文件末尾。忽略标签”:这个是相当神秘的;它指的是某个地方有一个属性值格式不正确,可能在文件末尾附近,因为文件末尾出现在属性值内部。浏览器不呈现链接的事实应该可以为我们提供一个很好的线索,告诉我们哪个元素出了问题。
- "看到文件结尾并且有打开的元素":这有点含糊,但基本上是指存在需要正确关闭的开放元素。行号指向文件的最后几行,并且此错误消息附带一行代码,指出打开元素的示例:
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
注意:缺少结束引号的属性可能会导致开放元素,因为文档的其余部分被解释为属性的内容。
¥Note: An attribute missing a closing quote can result in an open element because the rest of the document is interpreted as the attribute's content.
- “未封闭元素
ul”:这不是很有帮助,因为<ul>元素已正确关闭。出现此错误的原因是<a>元素由于缺少右引号而未关闭。
如果你无法弄清楚每条错误消息的含义,请不要担心 - 一个好主意是尝试一次修复一些错误。然后尝试重新验证你的 HTML 以显示还存在哪些错误。有时,修复较早的错误也会消除其他错误消息 - 多个错误通常可能由单个问题引起,形成多米诺骨牌效应。
¥If you can't work out what every error message means, don't worry about it — a good idea is to try fixing a few errors at a time. Then try revalidating your HTML to show what errors are left. Sometimes fixing an earlier error will also get rid of other error messages — several errors can often be caused by a single problem, in a domino effect.
当你在输出中看到以下横幅时,你就会知道所有错误何时得到修复:
¥You will know when all your errors are fixed when you see the following banner in your output:
![]()
概括
¥Summary
我们就这样介绍了调试 HTML,当你在以后的职业生涯中开始调试 CSS、JavaScript 和其他类型的代码时,这应该会为你提供一些有用的技能。这也标志着 HTML 模块简介学习文章的结束 - 现在你可以继续使用我们的评估来测试自己:第一个链接如下。
¥So there we have it, an introduction to debugging HTML, which should give you some useful skills to count on when you start to debug CSS, JavaScript, and other types of code later on in your career. This also marks the end of the Introduction to HTML module learning articles — now you can go on to testing yourself with our assessments: the first one is linked below.