JavaScript 类型数组
JavaScript 类型数组是类似数组的对象,它提供了一种在内存缓冲区中读取和写入原始二进制数据的机制。
¥JavaScript typed arrays are array-like objects that provide a mechanism for reading and writing raw binary data in memory buffers.
类型化数组无意取代数组来实现任何类型的功能。相反,它们为开发者提供了一个熟悉的界面来操作二进制数据。这在与平台功能交互时非常有用,例如音频和视频操作、使用 WebSockets 访问原始数据等等。JavaScript 类型数组中的每个条目都是原始二进制值,采用多种受支持格式之一,从 8 位整数到 64 位浮点数。
¥Typed arrays are not intended to replace arrays for any kind of functionality. Instead, they provide developers with a familiar interface for manipulating binary data. This is useful when interacting with platform features, such as audio and video manipulation, access to raw data using WebSockets, and so forth. Each entry in a JavaScript typed array is a raw binary value in one of a number of supported formats, from 8-bit integers to 64-bit floating-point numbers.
类型化数组对象与具有相似语义的数组共享许多相同的方法。但是,不要将类型化数组与普通数组混淆,因为在类型化数组上调用 Array.isArray() 将返回 false。此外,并非所有可用于普通数组的方法都受类型化数组支持(例如,push 和 pop)。
¥Typed array objects share many of the same methods as arrays with similar semantics. However, typed arrays are not to be confused with normal arrays, as calling Array.isArray() on a typed array returns false. Moreover, not all methods available for normal arrays are supported by typed arrays (e.g. push and pop).
为了实现最大的灵活性和效率,JavaScript 类型数组将实现分为缓冲区和视图。缓冲区是代表数据块的对象;它没有任何格式可言,也不提供访问其内容的机制。为了访问缓冲区中包含的内存,你需要使用 view。视图提供上下文,即数据类型、起始偏移量和元素数量。
¥To achieve maximum flexibility and efficiency, JavaScript typed arrays split the implementation into buffers and views. A buffer is an object representing a chunk of data; it has no format to speak of, and offers no mechanism for accessing its contents. In order to access the memory contained in a buffer, you need to use a view. A view provides a context — that is, a data type, starting offset, and number of elements.
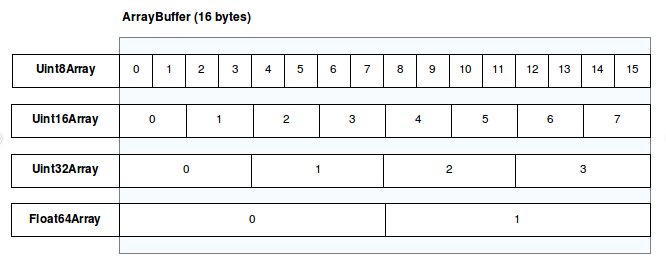
缓冲器
¥Buffers
有两种类型的缓冲区:ArrayBuffer 和 SharedArrayBuffer。两者都是内存跨度的底层表示。它们的名字中有 "array",但它们与数组没有太多关系 - 你不能直接读取或写入它们。相反,缓冲区是仅包含原始数据的通用对象。为了访问缓冲区表示的内存,你需要使用视图。
¥There are two types of buffers: ArrayBuffer and SharedArrayBuffer. Both are low-level representations of a memory span. They have "array" in their names, but they don't have much to do with arrays — you cannot read or write to them directly. Instead, buffers are generic objects that just contain raw data. In order to access the memory represented by a buffer, you need to use a view.
缓冲区支持以下操作:
¥Buffers support the following actions:
- 分配:一旦创建了新的缓冲区,就会分配新的内存范围并将其初始化为
0。 - 复制:使用
slice()方法,你可以高效地复制一部分内存,而无需创建视图来手动复制每个字节。 - 转移:使用
transfer()和transferToFixedLength()方法,你可以将内存范围的所有权转移到新的缓冲区对象。当在不同执行上下文之间传输数据而不进行复制时,这非常有用。传输完成后,原来的缓冲区不再可用。无法传输SharedArrayBuffer(因为缓冲区已被所有执行上下文共享)。 - 调整大小:使用
resize()方法,你可以调整内存跨度的大小(要么声明更多内存空间,只要不超过预先设置的maxByteLength限制,要么释放一些内存空间)。SharedArrayBuffer只能是 grown 但不能缩小。
ArrayBuffer 和 SharedArrayBuffer 之间的区别在于,前者始终一次由一个执行上下文拥有。如果将 ArrayBuffer 传递到不同的执行上下文,则该 ArrayBuffer 会被传输,而原始 ArrayBuffer 将变得不可用。这确保一次只有一个执行上下文可以访问内存。SharedArrayBuffer 在传递到不同的执行上下文时不会被传输,因此它可以同时被多个执行上下文访问。当多个线程访问同一内存范围时,这可能会引入竞争条件,因此诸如 Atomics 方法之类的操作变得有用。
¥The difference between ArrayBuffer and SharedArrayBuffer is that the former is always owned by a single execution context at a time. If you pass an ArrayBuffer to a different execution context, it is transferred and the original ArrayBuffer becomes unusable. This ensures that only one execution context can access the memory at a time. A SharedArrayBuffer is not transferred when passed to a different execution context, so it can be accessed by multiple execution contexts at the same time. This may introduce race conditions when multiple threads access the same memory span, so operations such as Atomics methods become useful.
意见
¥Views
目前主要有两种观点:类型化数组视图和 DataView。类型化数组提供 实用方法,允许你方便地转换二进制数据。DataView 级别更低,允许对数据访问方式进行精细控制。使用这两个视图读取和写入数据的方式非常不同。
¥There are currently two main kinds of views: typed array views and DataView. Typed arrays provide utility methods that allow you to conveniently transform binary data. DataView is more low-level and allows granular control of how data is accessed. The ways to read and write data using the two views are very different.
两种视图都会导致 ArrayBuffer.isView() 返回 true。它们都具有以下属性:
¥Both kinds of views cause ArrayBuffer.isView() to return true. They both have the following properties:
buffer-
视图引用的底层缓冲区。
byteOffset-
视图相对于缓冲区开头的偏移量(以字节为单位)。
byteLength-
视图的长度(以字节为单位)。
两个构造函数都接受上述三个作为单独的参数,尽管类型化数组构造函数接受 length 作为元素数而不是字节数。
¥Both constructors accept the above three as separate arguments, although typed array constructors accept length as the number of elements rather than the number of bytes.
类型化数组视图
¥Typed array views
类型化数组视图具有自描述性名称,并提供所有常见数字类型(如 Int8、Uint32、Float64 等)的视图。有一种特殊类型的数组视图 Uint8ClampedArray,它将值限制在 0 和 255 之间。例如,这对于 画布数据处理 很有用。
¥Typed array views have self-descriptive names and provide views for all the usual numeric types like Int8, Uint32, Float64 and so forth. There is one special typed array view, Uint8ClampedArray, which clamps the values between 0 and 255. This is useful for Canvas data processing, for example.
| 类型 | 值范围 | 大小(以字节为单位) | Web IDL 类型 |
|---|---|---|---|
Int8Array |
-128 至 127 | 1 | byte |
Uint8Array |
0 至 255 | 1 | octet |
Uint8ClampedArray |
0 至 255 | 1 | octet |
Int16Array |
-32768 至 32767 | 2 | short |
Uint16Array |
0 至 65535 | 2 | unsigned short |
Int32Array |
-2147483648 至 2147483647 | 4 | long |
Uint32Array |
0 至 4294967295 | 4 | unsigned long |
Float16Array |
-65504 至 65504 |
2 | N/A |
Float32Array |
-3.4e38 至 3.4e38 |
4 | unrestricted float |
Float64Array |
-1.8e308 至 1.8e308 |
8 | unrestricted double |
BigInt64Array |
-263 至 263 - 1 | 8 | bigint |
BigUint64Array |
0 到 264 - 1 | 8 | bigint |
所有类型化数组视图都具有相同的方法和属性,如 TypedArray 类所定义。它们仅在基础数据类型和字节大小方面有所不同。这在 值编码和标准化 中有更详细的讨论。
¥All typed array views have the same methods and properties, as defined by the TypedArray class. They only differ in the underlying data type and the size in bytes. This is discussed in more detail in Value encoding and normalization.
原则上,类型化数组是固定长度的,因此可能改变数组长度的数组方法不可用。这包括 pop、push、shift、splice 和 unshift。此外,flat 不可用,因为没有嵌套类型数组,而相关方法(包括 concat 和 flatMap)没有很好的用例,因此不可用。由于 splice 不可用,因此 toSpliced 也不可用。所有其他数组方法在 Array 和 TypedArray 之间共享。
¥Typed arrays are, in principle, fixed-length, so array methods that may change the length of an array are not available. This includes pop, push, shift, splice, and unshift. In addition, flat is unavailable because there are no nested typed arrays, and related methods including concat and flatMap do not have great use cases so are unavailable. As splice is unavailable, so too is toSpliced. All other array methods are shared between Array and TypedArray.
另一方面,TypedArray 具有额外的 set 和 subarray 方法,可以优化查看同一缓冲区的多个类型数组的工作。set() 方法允许使用来自另一个数组或类型化数组的数据一次设置多个类型化数组索引。如果两个类型化数组共享相同的底层缓冲区,则操作可能会更有效,因为它是快速内存移动。subarray() 方法创建一个新的类型化数组视图,该视图引用与原始类型化数组相同的缓冲区,但跨度更窄。
¥On the other hand, TypedArray has the extra set and subarray methods that optimize working with multiple typed arrays that view the same buffer. The set() method allows setting multiple typed array indices at once, using data from another array or typed array. If the two typed arrays share the same underlying buffer, the operation may be more efficient as it's a fast memory move. The subarray() method creates a new typed array view that references the same buffer as the original typed array, but with a narrower span.
无法在不更改底层缓冲区的情况下直接更改类型化数组的长度。但是,当类型化数组查看可调整大小的缓冲区并且没有固定的 byteLength 时,它是长度跟踪的,并且会在调整大小的缓冲区大小时自动调整大小以适合底层缓冲区。详情请参见 查看可调整大小的缓冲区时的行为。
¥There's no way to directly change the length of a typed array without changing the underlying buffer. However, when the typed array views a resizable buffer and does not have a fixed byteLength, it is length-tracking, and will automatically resize to fit the underlying buffer as the resizable buffer is resized. See Behavior when viewing a resizable buffer for details.
与常规数组类似,你可以使用 括号表示法 访问类型化数组元素。检索底层缓冲区中的相应字节并将其解释为数字。使用数字(或数字的字符串表示形式,因为访问属性时数字总是转换为字符串)的任何属性访问都将由类型化数组代理 - 它们从不与对象本身交互。这意味着,例如:
¥Similar to regular arrays, you can access typed array elements using bracket notation. The corresponding bytes in the underlying buffer are retrieved and interpreted as a number. Any property access using a number (or the string representation of a number, since numbers are always converted to strings when accessing properties) will be proxied by the typed array — they never interact with the object itself. This means, for example:
- 越界索引访问始终返回
undefined,而不实际访问对象的属性。 - 任何写入此类越界属性的尝试都不会产生任何效果:它不会引发错误,但也不会更改缓冲区或类型化数组。
- 类型化数组索引似乎是可配置和可写的,但任何更改其属性的尝试都将失败。
const uint8 = new Uint8Array([1, 2, 3]);
console.log(uint8[0]); // 1
// For illustrative purposes only. Not for production code.
uint8[-1] = 0;
uint8[2.5] = 0;
uint8[NaN] = 0;
console.log(Object.keys(uint8)); // ["0", "1", "2"]
console.log(uint8[NaN]); // undefined
// Non-numeric access still works
uint8[true] = 0;
console.log(uint8[true]); // 0
Object.freeze(uint8); // TypeError: Cannot freeze array buffer views with elements
DataView
DataView 是一个底层接口,提供 getter/setter API 来读取任意数据并将其写入缓冲区。例如,这在处理不同类型的数据时非常有用。类型化数组视图采用平台的原生字节顺序(请参阅 字节顺序)。使用 DataView,可以控制字节顺序。默认情况下,它是大端字节序 - 字节按从最高有效到最低有效的顺序排列。这可以颠倒过来,使用 getter/setter 方法将字节从最低有效位到最高有效位(小端)排序。
¥The DataView is a low-level interface that provides a getter/setter API to read and write arbitrary data to the buffer. This is useful when dealing with different types of data, for example. Typed array views are in the native byte-order (see Endianness) of your platform. With a DataView, the byte-order can be controlled. By default, it's big-endian—the bytes are ordered from most significant to least significant. This can be reversed, with the bytes ordered from least significant to most significant (little-endian), using getter/setter methods.
DataView 不需要对齐;多字节读写可以从任意指定的偏移量开始。setter 方法的工作方式相同。
¥DataView does not require alignment; multi-byte read and write can be started at any specified offset. The setter methods work the same way.
以下示例使用 DataView 来获取任意数字的二进制表示形式:
¥The following example uses a DataView to get the binary representation of any number:
function toBinary(
x,
{ type = "Float64", littleEndian = false, separator = " ", radix = 16 } = {},
) {
const bytesNeeded = globalThis[`${type}Array`].BYTES_PER_ELEMENT;
const dv = new DataView(new ArrayBuffer(bytesNeeded));
dv[`set${type}`](0, x, littleEndian);
const bytes = Array.from({ length: bytesNeeded }, (_, i) =>
dv
.getUint8(i)
.toString(radix)
.padStart(8 / Math.log2(radix), "0"),
);
return bytes.join(separator);
}
console.log(toBinary(1.1)); // 3f f1 99 99 99 99 99 9a
console.log(toBinary(1.1, { littleEndian: true })); // 9a 99 99 99 99 99 f1 3f
console.log(toBinary(20, { type: "Int8", radix: 2 })); // 00010100
使用类型化数组的 Web API
¥Web APIs using typed arrays
这些是使用类型化数组的 API 的一些示例;还有其他的,并且一直在添加更多。
¥These are some examples of APIs that make use of typed arrays; there are others, and more are being added all the time.
FileReader.prototype.readAsArrayBuffer()-
FileReader.prototype.readAsArrayBuffer()方法开始读取指定的Blob或File的内容。 fetch()-
fetch()的body选项可以是类型化数组或ArrayBuffer,使你能够将这些对象作为POST请求的有效负载发送。 ImageData.data-
Uint8ClampedArray表示一维数组,其中包含按 RGBA 顺序排列的数据,整数值介于0和255之间(包含0和255)。
示例
使用带缓冲区的视图
¥Using views with buffers
首先,我们需要创建一个缓冲区,这里的固定长度为 16 字节:
¥First of all, we will need to create a buffer, here with a fixed length of 16-bytes:
const buffer = new ArrayBuffer(16);
此时,我们就有了一块内存,其字节全部预先初始化为 0。不过,我们能用它做的事情并不多。例如,我们可以确认缓冲区的大小正确:
¥At this point, we have a chunk of memory whose bytes are all pre-initialized to 0. There's not a lot we can do with it, though. For example, we can confirm that the buffer is the right size:
if (buffer.byteLength === 16) {
console.log("Yes, it's 16 bytes.");
} else {
console.log("Oh no, it's the wrong size!");
}
在我们真正使用这个缓冲区之前,我们需要创建一个视图。让我们创建一个视图,将缓冲区中的数据视为 32 位有符号整数数组:
¥Before we can really work with this buffer, we need to create a view. Let's create a view that treats the data in the buffer as an array of 32-bit signed integers:
const int32View = new Int32Array(buffer);
现在我们可以像普通数组一样访问数组中的字段:
¥Now we can access the fields in the array just like a normal array:
for (let i = 0; i < int32View.length; i++) {
int32View[i] = i * 2;
}
这将用值 0、2、4 和 6 填充数组中的 4 个条目(4 个条目,每个条目 4 个字节,总共 16 个字节)。
¥This fills out the 4 entries in the array (4 entries at 4 bytes each makes 16 total bytes) with the values 0, 2, 4, and 6.
对同一数据的多个视图
¥Multiple views on the same data
当你考虑可以对同一数据创建多个视图时,事情开始变得非常有趣。例如,给出上面的代码,我们可以这样继续:
¥Things start to get really interesting when you consider that you can create multiple views onto the same data. For example, given the code above, we can continue like this:
const int16View = new Int16Array(buffer);
for (let i = 0; i < int16View.length; i++) {
console.log(`Entry ${i}: ${int16View[i]}`);
}
这里我们创建一个 16 位整数视图,它与现有的 32 位视图共享相同的缓冲区,并将缓冲区中的所有值输出为 16 位整数。现在我们得到输出 0, 0, 2, 0, 4, 0, 6, 0(假设是小端编码):
¥Here we create a 16-bit integer view that shares the same buffer as the existing 32-bit view and we output all the values in the buffer as 16-bit integers. Now we get the output 0, 0, 2, 0, 4, 0, 6, 0 (assuming little-endian encoding):
Int16Array | 0 | 0 | 2 | 0 | 4 | 0 | 6 | 0 | Int32Array | 0 | 2 | 4 | 6 | ArrayBuffer | 00 00 00 00 | 02 00 00 00 | 04 00 00 00 | 06 00 00 00 |
不过,你还可以更进一步。考虑一下:
¥You can go a step farther, though. Consider this:
int16View[0] = 32;
console.log(`Entry 0 in the 32-bit array is now ${int32View[0]}`);
其输出是 "Entry 0 in the 32-bit array is now 32"。
¥The output from this is "Entry 0 in the 32-bit array is now 32".
换句话说,这两个数组确实是在同一个数据缓冲区上查看的,将其视为不同的格式。
¥In other words, the two arrays are indeed viewed on the same data buffer, treating it as different formats.
Int16Array | 32 | 0 | 2 | 0 | 4 | 0 | 6 | 0 | Int32Array | 32 | 2 | 4 | 6 | ArrayBuffer | 20 00 00 00 | 02 00 00 00 | 04 00 00 00 | 06 00 00 00 |
你可以使用任何视图类型执行此操作,但如果你设置一个整数然后将其读取为浮点数,你可能会得到一个奇怪的结果,因为这些位的解释不同。
¥You can do this with any view type, although if you set an integer and then read it as a floating-point number, you will probably get a strange result because the bits are interpreted differently.
const float32View = new Float32Array(buffer);
console.log(float32View[0]); // 4.484155085839415e-44
从缓冲区读取文本
¥Reading text from a buffer
缓冲区并不总是代表数字。例如,读取文件可以为你提供文本数据缓冲区。你可以使用类型化数组从缓冲区中读取此数据。
¥Buffers don't always represent numbers. For example, reading a file can give you a text data buffer. You can read this data out of the buffer using a typed array.
以下使用 TextDecoder Web API 读取 UTF-8 文本:
¥The following reads UTF-8 text using the TextDecoder web API:
const buffer = new ArrayBuffer(8);
const uint8 = new Uint8Array(buffer);
// Data manually written here, but pretend it was already in the buffer
uint8.set([228, 189, 160, 229, 165, 189]);
const text = new TextDecoder().decode(uint8);
console.log(text); // "你好"
下面使用 String.fromCharCode() 方法读取 UTF-16 文本:
¥The following reads UTF-16 text using the String.fromCharCode() method:
const buffer = new ArrayBuffer(8);
const uint16 = new Uint16Array(buffer);
// Data manually written here, but pretend it was already in the buffer
uint16.set([0x4f60, 0x597d]);
const text = String.fromCharCode(...uint16);
console.log(text); // "你好"
处理复杂的数据结构
¥Working with complex data structures
通过将单个缓冲区与不同类型的多个视图相结合(从缓冲区的不同偏移量开始),你可以与包含多种数据类型的数据对象进行交互。例如,这使你可以与 WebGL 或数据文件中的复杂数据结构进行交互。
¥By combining a single buffer with multiple views of different types, starting at different offsets into the buffer, you can interact with data objects containing multiple data types. This lets you, for example, interact with complex data structures from WebGL or data files.
考虑这个 C 结构:
¥Consider this C structure:
struct someStruct {
unsigned long id;
char username[16];
float amountDue;
};
你可以像这样访问包含这种格式的数据的缓冲区:
¥You can access a buffer containing data in this format like this:
const buffer = new ArrayBuffer(24);
// ... read the data into the buffer ...
const idView = new Uint32Array(buffer, 0, 1);
const usernameView = new Uint8Array(buffer, 4, 16);
const amountDueView = new Float32Array(buffer, 20, 1);
然后你可以访问例如 amountDueView[0] 应付的金额。
¥Then you can access, for example, the amount due with amountDueView[0].
注意:C 结构中的 数据结构对齐 与平台相关。针对这些填充差异采取预防措施和考虑因素。
¥Note: The data structure alignment in a C structure is platform-dependent. Take precautions and considerations for these padding differences.
转换为普通数组
¥Conversion to normal arrays
处理类型化数组后,有时将其转换回普通数组以便从 Array 原型中受益。这可以使用 Array.from() 来完成:
¥After processing a typed array, it is sometimes useful to convert it back to a normal array in order to benefit from the Array prototype. This can be done using Array.from():
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = Array.from(typedArray);
以及 扩展语法:
¥as well as the spread syntax:
const typedArray = new Uint8Array([1, 2, 3, 4]);
const normalArray = [...typedArray];
也可以看看
¥See also
- hacks.mozilla.org 上的 使用类型化数组更快地操作画布像素 (2011)
- web.dev 上的 类型化数组 - 浏览器中的二进制数据 (2012)
- 字节顺序
ArrayBufferDataViewTypedArraySharedArrayBuffer