从服务器获取数据
现代网站和应用中的另一个非常常见的任务是从服务器检索单个数据项以更新网页的各个部分,而无需加载整个新页面。这个看似很小的细节对网站的性能和行为产生了巨大的影响,因此在本文中,我们将解释这个概念并研究使其成为可能的技术:特别是 获取 API。
¥Another very common task in modern websites and applications is retrieving individual data items from the server to update sections of a webpage without having to load an entire new page. This seemingly small detail has had a huge impact on the performance and behavior of sites, so in this article, we'll explain the concept and look at technologies that make it possible: in particular, the Fetch API.
| 先决条件: | JavaScript 基础知识(参见 第一步、 架构模块、 JavaScript 对象)、 客户端 API 基础知识 |
|---|---|
| 目标: | 了解如何从服务器获取数据并使用它来更新网页的内容。 |
这里有什么问题?
¥What is the problem here?
网页由 HTML 页面和(通常)各种其他文件组成,例如样式表、脚本和图片。Web 上页面加载的基本模型是,你的浏览器向服务器发出一个或多个 HTTP 请求,以获取显示页面所需的文件,然后服务器以所请求的文件进行响应。如果你访问另一个页面,浏览器会请求新文件,服务器会用它们进行响应。
¥A web page consists of an HTML page and (usually) various other files, such as stylesheets, scripts, and images. The basic model of page loading on the Web is that your browser makes one or more HTTP requests to the server for the files needed to display the page, and the server responds with the requested files. If you visit another page, the browser requests the new files, and the server responds with them.

该模型非常适合许多网站。但考虑一个非常数据驱动的网站。例如,像 温哥华公共库 这样的库网站。除其他外,你可以将这样的站点视为数据库的用户界面。它可能会让你搜索特定类型的书籍,或者可能会根据你以前借过的书籍向你推荐你可能喜欢的书籍。当你执行此操作时,它需要使用要显示的新书籍集更新页面。但请注意,大部分页面内容(包括页眉、侧边栏和页脚等项目)保持不变。
¥This model works perfectly well for many sites. But consider a website that's very data-driven. For example, a library website like the Vancouver Public Library. Among other things you could think of a site like this as a user interface to a database. It might let you search for a particular genre of book, or might show you recommendations for books you might like, based on books you've previously borrowed. When you do this, it needs to update the page with the new set of books to display. But note that most of the page content — including items like the page header, sidebar, and footer — stays the same.
传统模型的问题在于,我们必须获取并加载整个页面,即使我们只需要更新其中的一部分。这是低效的并且会导致糟糕的用户体验。
¥The trouble with the traditional model here is that we'd have to fetch and load the entire page, even when we only need to update one part of it. This is inefficient and can result in a poor user experience.
因此,许多网站没有使用传统模型,而是使用 JavaScript API 向服务器请求数据并更新页面内容,而无需加载页面。因此,当用户搜索新产品时,浏览器仅请求更新页面所需的数据,例如要显示的一组新书。
¥So instead of the traditional model, many websites use JavaScript APIs to request data from the server and update the page content without a page load. So when the user searches for a new product, the browser only requests the data which is needed to update the page — the set of new books to display, for instance.

这里的主要 API 是 获取 API。这使得页面中运行的 JavaScript 能够向服务器发出 HTTP 请求以检索特定资源。当服务器提供它们时,JavaScript 可以使用这些数据来更新页面,通常使用 DOM 操作 API。请求的数据通常是 JSON,这是传输结构化数据的良好格式,但也可以是 HTML 或只是文本。
¥The main API here is the Fetch API. This enables JavaScript running in a page to make an HTTP request to a server to retrieve specific resources. When the server provides them, the JavaScript can use the data to update the page, typically by using DOM manipulation APIs. The data requested is often JSON, which is a good format for transferring structured data, but can also be HTML or just text.
这是 Amazon、YouTube、eBay 等数据驱动网站的常见模式。有了这个模型:
¥This is a common pattern for data-driven sites such as Amazon, YouTube, eBay, and so on. With this model:
- 页面更新速度要快得多,你不必等待页面刷新,这意味着网站感觉更快、响应更灵敏。
- 每次更新下载的数据更少,这意味着带宽浪费更少。对于宽带连接的台式机来说,这可能不是一个大问题,但对于移动设备以及没有无处不在的快速互联网服务的国家来说,这是一个主要问题。
注意:早期,这种通用技术被称为 异步 JavaScript 和 XML (Ajax),因为它倾向于请求 XML 数据。如今通常情况并非如此(你更有可能请求 JSON),但结果仍然相同,并且术语 "Ajax" 仍然经常用于描述该技术。
¥Note: In the early days, this general technique was known as Asynchronous JavaScript and XML (Ajax), because it tended to request XML data. This is normally not the case these days (you'd be more likely to request JSON), but the result is still the same, and the term "Ajax" is still often used to describe the technique.
为了进一步加快速度,一些网站还在用户首次请求时将资源和数据存储在用户的计算机上,这意味着在后续访问中,他们使用本地版本,而不是每次首次加载页面时下载新副本。内容仅在更新后才从服务器重新加载。
¥To speed things up even further, some sites also store assets and data on the user's computer when they are first requested, meaning that on subsequent visits they use the local versions instead of downloading fresh copies every time the page is first loaded. The content is only reloaded from the server when it has been updated.
获取 API
获取文本内容
¥Fetching text content
对于此示例,我们将从几个不同的文本文件中请求数据并使用它们来填充内容区域。
¥For this example, we'll request data out of a few different text files and use them to populate a content area.
这一系列文件将充当我们的假数据库;在实际应用中,我们更有可能使用服务器端语言(例如 PHP、Python 或 Node)从数据库请求数据。然而,在这里,我们希望保持简单并专注于其中的客户端部分。
¥This series of files will act as our fake database; in a real application, we'd be more likely to use a server-side language like PHP, Python, or Node to request our data from a database. Here, however, we want to keep it simple and concentrate on the client-side part of this.
要开始此示例,请在计算机上的新目录中制作 fetch-start.html 和四个文本文件(verse1.txt、verse2.txt、verse3.txt 和 verse4.txt)的本地副本。在此示例中,当在下拉菜单中选择该诗时,我们将获取该诗的另一节经文(你可能很熟悉)。
¥To begin this example, make a local copy of fetch-start.html and the four text files — verse1.txt, verse2.txt, verse3.txt, and verse4.txt — in a new directory on your computer. In this example, we will fetch a different verse of the poem (which you may well recognize) when it's selected in the drop-down menu.
在 <script> 元素内添加以下代码。这将存储对 <select> 和 <pre> 元素的引用,并向 <select> 元素添加监听器,以便当用户选择新值时,新值将作为参数传递给名为 updateDisplay() 的函数。
¥Just inside the <script> element, add the following code. This stores references to the <select> and <pre> elements and adds a listener to the <select> element, so that when the user selects a new value, the new value is passed to the function named updateDisplay() as a parameter.
const verseChoose = document.querySelector("select");
const poemDisplay = document.querySelector("pre");
verseChoose.addEventListener("change", () => {
const verse = verseChoose.value;
updateDisplay(verse);
});
让我们定义 updateDisplay() 函数。首先,将以下内容放在之前的代码块下方 - 这是该函数的空壳。
¥Let's define our updateDisplay() function. First of all, put the following beneath your previous code block — this is the empty shell of the function.
function updateDisplay(verse) {
}
我们将通过构造一个指向我们要加载的文本文件的相对 URL 来启动我们的函数,因为稍后我们将需要它。任何时候 <select> 元素的值都与所选 <option> 内的文本相同(除非你在值属性中指定不同的值),例如 "第 1 节"。对应的经文文件是 "verse1.txt",与 HTML 文件在同一目录下,因此只需文件名即可。
¥We'll start our function by constructing a relative URL pointing to the text file we want to load, as we'll need it later. The value of the <select> element at any time is the same as the text inside the selected <option> (unless you specify a different value in a value attribute) — so for example "Verse 1". The corresponding verse text file is "verse1.txt", and is in the same directory as the HTML file, therefore just the file name will do.
但是,Web 服务器往往区分大小写,并且文件名中不包含空格。要将 "第 1 节" 转换为 "verse1.txt",我们需要将 'V' 转换为小写,删除空格,并在末尾添加 ".txt"。这可以通过 replace()、toLowerCase() 和 模板文字 来完成。在 updateDisplay() 函数中添加以下行:
¥However, web servers tend to be case-sensitive, and the file name doesn't have a space in it. To convert "Verse 1" to "verse1.txt" we need to convert the 'V' to lower case, remove the space, and add ".txt" on the end. This can be done with replace(), toLowerCase(), and template literal. Add the following lines inside your updateDisplay() function:
verse = verse.replace(" ", "").toLowerCase();
const url = `${verse}.txt`;
最后我们准备好使用 Fetch API:
¥Finally we're ready to use the Fetch API:
// Call `fetch()`, passing in the URL.
fetch(url)
// fetch() returns a promise. When we have received a response from the server,
// the promise's `then()` handler is called with the response.
.then((response) => {
// Our handler throws an error if the request did not succeed.
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
// Otherwise (if the response succeeded), our handler fetches the response
// as text by calling response.text(), and immediately returns the promise
// returned by `response.text()`.
return response.text();
})
// When response.text() has succeeded, the `then()` handler is called with
// the text, and we copy it into the `poemDisplay` box.
.then((text) => {
poemDisplay.textContent = text;
})
// Catch any errors that might happen, and display a message
// in the `poemDisplay` box.
.catch((error) => {
poemDisplay.textContent = `Could not fetch verse: ${error}`;
});
这里有很多东西需要解压。
¥There's quite a lot to unpack in here.
首先,Fetch API 的入口点是一个名为 fetch() 的全局函数,它将 URL 作为参数(它需要另一个可选参数来进行自定义设置,但我们在这里不使用它)。
¥First, the entry point to the Fetch API is a global function called fetch(), that takes the URL as a parameter (it takes another optional parameter for custom settings, but we're not using that here).
接下来,fetch() 是一个异步 API,它返回 Promise。如果你不知道那是什么,请阅读 异步 JavaScript 上的模块,特别是 promises 上的文章,然后返回此处。你会发现该文章还讨论了 fetch() API!
¥Next, fetch() is an asynchronous API which returns a Promise. If you don't know what that is, read the module on asynchronous JavaScript, and in particular the article on promises, then come back here. You'll find that article also talks about the fetch() API!
因此,因为 fetch() 返回一个 Promise,所以我们将一个函数传递到返回的 Promise 的 then() 方法中。当 HTTP 请求收到服务器的响应时,将调用此方法。在处理程序中,我们检查请求是否成功,如果没有成功则抛出错误。否则,我们调用 response.text(),以获取文本形式的响应正文。
¥So because fetch() returns a promise, we pass a function into the then() method of the returned promise. This method will be called when the HTTP request has received a response from the server. In the handler, we check that the request succeeded, and throw an error if it didn't. Otherwise, we call response.text(), to get the response body as text.
事实证明,response.text() 也是异步的,所以我们返回它返回的 promise,并将一个函数传递到这个新 promise 的 then() 方法中。当响应文本准备好时,将调用此函数,并且在其中我们将使用文本更新 <pre> 块。
¥It turns out that response.text() is also asynchronous, so we return the promise it returns, and pass a function into the then() method of this new promise. This function will be called when the response text is ready, and inside it we will update our <pre> block with the text.
最后,我们在末尾链接一个 catch() 处理程序,以捕获我们调用的异步函数或其处理程序中抛出的任何错误。
¥Finally, we chain a catch() handler at the end, to catch any errors thrown in either of the asynchronous functions we called or their handlers.
该示例的一个问题是,它在第一次加载时不会显示任何诗歌。要解决此问题,请在代码底部(就在结束 </script> 标记上方)添加以下两行以默认加载第 1 节,并确保 <select> 元素始终显示正确的值:
¥One problem with the example as it stands is that it won't show any of the poem when it first loads. To fix this, add the following two lines at the bottom of your code (just above the closing </script> tag) to load verse 1 by default, and make sure the <select> element always shows the correct value:
updateDisplay("Verse 1");
verseChoose.value = "Verse 1";
从服务器提供你的示例
¥Serving your example from a server
如果你只是从本地文件运行示例,现代浏览器将不会运行 HTTP 请求。这是因为安全限制(有关网络安全的更多信息,请阅读 网站安全)。
¥Modern browsers will not run HTTP requests if you just run the example from a local file. This is because of security restrictions (for more on web security, read Website security).
为了解决这个问题,我们需要通过本地 Web 服务器运行示例来测试该示例。要了解如何执行此操作,请阅读 我们设置本地测试服务器的指南。
¥To get around this, we need to test the example by running it through a local web server. To find out how to do this, read our guide to setting up a local testing server.
可以储存
¥The can store
在此示例中,我们创建了一个名为 The Can Store 的示例网站 - 这是一个虚构的超市,只销售罐头食品。你可以找到这个 示例位于 GitHub 上 和 查看源代码。
¥In this example we have created a sample site called The Can Store — it's a fictional supermarket that only sells canned goods. You can find this example live on GitHub, and see the source code.
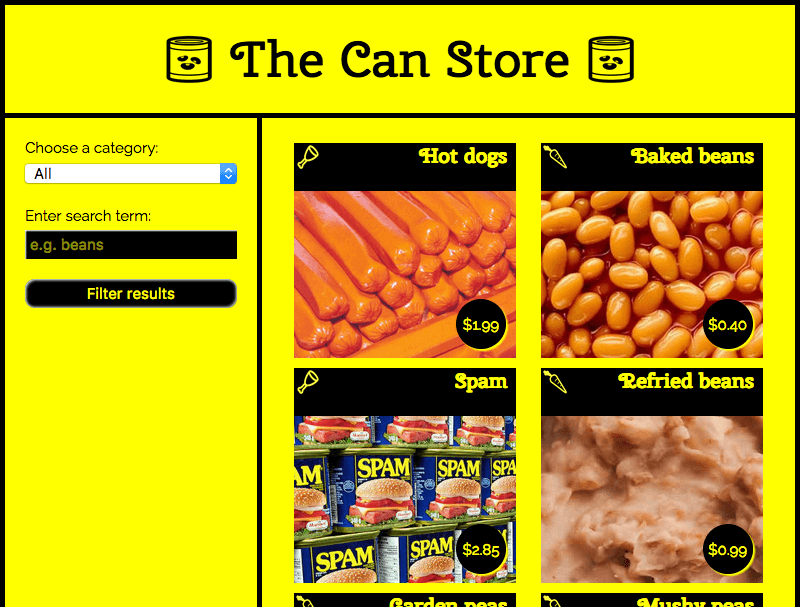
默认情况下,网站显示所有产品,但你可以使用左侧列中的表单控件按类别和/或搜索词过滤它们。
¥By default, the site displays all the products, but you can use the form controls in the left-hand column to filter them by category, or search term, or both.
有大量复杂的代码用于按类别和搜索词过滤产品、操作字符串以便数据在 UI 中正确显示等。我们不会在本文中讨论所有内容,但你可以找到大量的代码 代码中的注释(参见 can-script.js)。
¥There is quite a lot of complex code that deals with filtering the products by category and search terms, manipulating strings so the data displays correctly in the UI, etc. We won't discuss all of it in the article, but you can find extensive comments in the code (see can-script.js).
不过,我们将解释 Fetch 代码。
¥We will, however, explain the Fetch code.
第一个使用 Fetch 的块可以在 JavaScript 的开头找到:
¥The first block that uses Fetch can be found at the start of the JavaScript:
fetch("products.json")
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
return response.json();
})
.then((json) => initialize(json))
.catch((err) => console.error(`Fetch problem: ${err.message}`));
fetch() 函数返回一个承诺。如果成功完成,第一个 .then() 块内的函数将包含从网络返回的 response。
¥The fetch() function returns a promise. If this completes successfully, the function inside the first .then() block contains the response returned from the network.
在这个函数中我们:
¥Inside this function we:
- 检查服务器是否没有返回错误(例如
404 Not Found)。如果确实如此,我们会抛出错误。 - 致电
json()响应。这会将数据检索为 JSON 对象。我们返回response.json()返回的承诺。
接下来,我们将一个函数传递到返回的 Promise 的 then() 方法中。该函数将传递一个包含 JSON 格式的响应数据的对象,我们将其传递给 initialize() 函数。此函数启动在用户界面中显示所有产品的过程。
¥Next we pass a function into the then() method of that returned promise. This function will be passed an object containing the response data as JSON, which we pass into the initialize() function. This function which starts the process of displaying all the products in the user interface.
为了处理错误,我们将 .catch() 块链接到链的末尾。如果承诺由于某种原因失败,则会运行。在其中,我们包含一个作为参数传递的函数,即 err 对象。该 err 对象可用于报告已发生错误的性质,在本例中我们使用简单的 console.error() 来执行此操作。
¥To handle errors, we chain a .catch() block onto the end of the chain. This runs if the promise fails for some reason. Inside it, we include a function that is passed as a parameter, an err object. This err object can be used to report the nature of the error that has occurred, in this case we do it with a simple console.error().
然而,一个完整的网站可以通过在用户屏幕上显示一条消息并可能提供纠正这种情况的选项来更优雅地处理此错误,但我们只需要一个简单的 console.error()。
¥However, a complete website would handle this error more gracefully by displaying a message on the user's screen and perhaps offering options to remedy the situation, but we don't need anything more than a simple console.error().
你可以自行测试失败案例:
¥You can test the failure case yourself:
- 制作示例文件的本地副本。
- 通过 Web 服务器运行代码(如上所述,在 从服务器提供你的示例 中)。
- 将要获取的文件的路径修改为 'produc.json' 之类的内容(确保拼写错误)。
- 现在在浏览器中加载索引文件(通过
localhost:8000)并在浏览器开发者控制台中查看。你将看到类似“获取问题:HTTP 错误:404".
第二个 Fetch 块可以在 fetchBlob() 函数内找到:
¥The second Fetch block can be found inside the fetchBlob() function:
fetch(url)
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
return response.blob();
})
.then((blob) => showProduct(blob, product))
.catch((err) => console.error(`Fetch problem: ${err.message}`));
这与前一个的工作方式非常相似,只是我们使用 blob() 代替 json()。在本例中,我们希望将响应作为图片文件返回,我们使用的数据格式是 Blob(该术语是 "二进制大对象" 的缩写,基本上可用于表示大型文件类对象,例如图片或视频) 文件)。
¥This works in much the same way as the previous one, except that instead of using json(), we use blob(). In this case we want to return our response as an image file, and the data format we use for that is Blob (the term is an abbreviation of "Binary Large Object" and can basically be used to represent large file-like objects, such as images or video files).
一旦我们成功收到了 blob,我们就把它传递给 showProduct() 函数,该函数会显示它。
¥Once we've successfully received our blob, we pass it into our showProduct() function, which displays it.
XMLHttpRequest API
有时,尤其是在较旧的代码中,你会看到另一个名为 XMLHttpRequest(通常缩写为 "XHR")的 API 用于发出 HTTP 请求。它早于 Fetch,并且实际上是第一个广泛用于实现 AJAX 的 API。如果可以的话,我们建议你使用 Fetch:它比 XMLHttpRequest 更简单,并且具有更多功能。我们不会介绍使用 XMLHttpRequest 的示例,但我们将向你展示第一个可以存储请求的 XMLHttpRequest 版本是什么样子:
¥Sometimes, especially in older code, you'll see another API called XMLHttpRequest (often abbreviated as "XHR") used to make HTTP requests. This predated Fetch, and was really the first API widely used to implement AJAX. We recommend you use Fetch if you can: it's a simpler API and has more features than XMLHttpRequest. We won't go through an example that uses XMLHttpRequest, but we will show you what the XMLHttpRequest version of our first can store request would look like:
const request = new XMLHttpRequest();
try {
request.open("GET", "products.json");
request.responseType = "json";
request.addEventListener("load", () => initialize(request.response));
request.addEventListener("error", () => console.error("XHR error"));
request.send();
} catch (error) {
console.error(`XHR error ${request.status}`);
}
这有五个阶段:
¥There are five stages to this:
- 创建一个新的
XMLHttpRequest对象。 - 调用其
open()方法对其进行初始化。 - 将事件监听器添加到其
load事件,该事件监听器在响应成功完成时触发。在监听器中,我们使用数据调用initialize()。 - 为其
error事件添加事件监听器,该事件监听器在请求遇到错误时触发 - 发送请求。
我们还必须将整个内容封装在 try...catch 块中,以处理 open() 或 send() 引发的任何错误。
¥We also have to wrap the whole thing in the try...catch block, to handle any errors thrown by open() or send().
希望你认为 Fetch API 对此有所改进。特别是,看看我们如何处理两个不同地方的错误。
¥Hopefully you think the Fetch API is an improvement over this. In particular, see how we have to handle errors in two different places.
概括
也可以看看
¥See also
然而,本文讨论了许多不同的主题,这只是真正触及了表面。有关这些主题的更多详细信息,请尝试以下文章:
¥There are however a lot of different subjects discussed in this article, which has only really scratched the surface. For a lot more detail on these subjects, try the following articles: